
Amazon AWS事故和架构分析
2月28日,Amazon AWS出了一个大事故,成千上万使用AWS云服务的网站不能被访问了,页面,文件,照片,还有视频不能被存取。整个事故持续了超过四个小时。这个事故致使互联网上前一百家零售商中的54家的网站性能下降20%或更多。据专门从事网络风险评估的Cyence公司估计,Amazond的损失在1亿五千万美元以上【1】
以下是这个事故的回放(太平洋时间):
2月28日早上,Amazon S3团队发现S3的北弗吉尼亚地区的计费系统性能比预期的下降了,于是他们开始查错。
早上9点37分:S3的工程师想关闭一些服务器,很不幸,一条命令参数错了,一些不该被关闭的服务器被关闭了。这下悲剧了,这个地区的S3存储服务宕了。与此同时,依赖于S3存储服务的S3 console, Amazon Elastic Compute Cloud (EC2) 新的实例的建立, Amazon Elastic Block Store (EBS) volumes, 和AWS Lambda等都被影响到。
中午12点26分:S3的GET, LIST, 和DELETE API功能开始恢复
下午1点18分:S3的GET, LIST, 和DELETE API恢复正常,但还是不能做PUT操作。
下午1点54分:S3存储功能恢复正常。与其相关的其它功能也开始恢复。
一条命令一亿五千万美元,这估计是世界上最贵的命令了。希望发出这命令的哥们还好,没有被Amazon以临时工的名义开除。这真不能全怪他,Amazon AWS的架构其实是有问题,所以才造成了如此悲剧。
AWS全球服务分布在16个地区(region),每个地区有多个冗余区(zone),每个地区的冗余区之间是用高速,专用的光纤网络连接。一般来说,用户会选择离用户或其客户最近的地区建立用户的私有云,在这个地区使用一个或多个冗余区。如果使用多余一个冗余区,可以保证即便在其它冗余区宕机时,业务不受影响。为了更高的可靠性,也可以将业务分布到多个地区。这次有的公司只使用北弗吉尼亚地区的数据中心,就受到了影响。有的公司业务在多个地区冗余,基本上不受影响。但多个地区的冗余会提高成本,运行复杂度,所以不是所有公司都采用。
下图是AWS再全球的数据中心,图中每个圆圈是一个地区(橙色的圆圈代表已有的,绿色的圆圈代表在建),圆圈中的数字表示有几个冗余区:
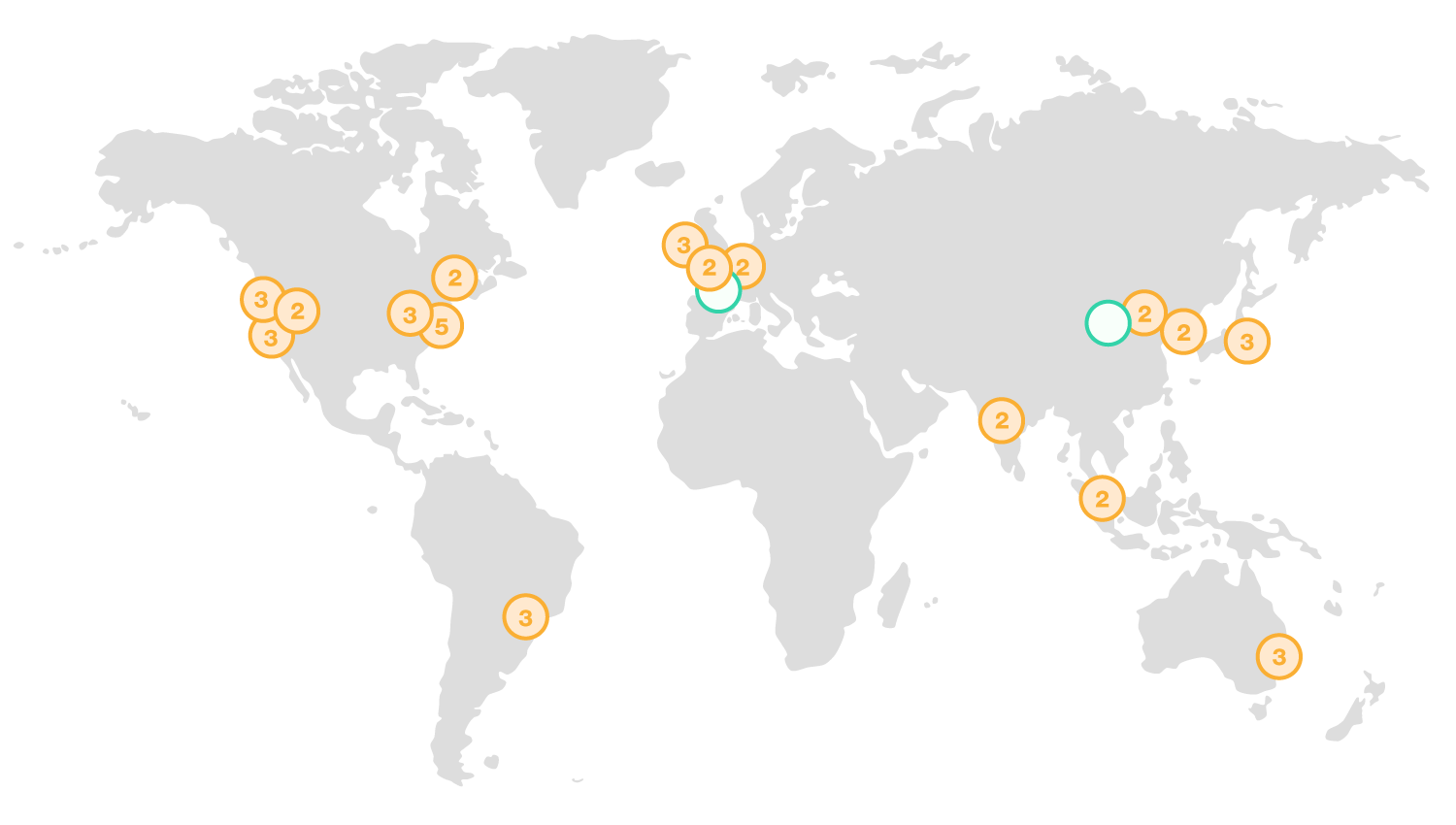
下表是各个地区代号和名称:
| 地区代号 | 地区名 |
|---|---|
| us-east-1 | US East (N. Virginia) |
| us-east-2 | US East (Ohio) |
| us-west-1 | US West (N. California) |
| us-west-1 | US West (Oregon) |
| us-west-2 | US West (N. California) |
| ca-central-1 | Canada (Central) |
| eu-west-1 | EU (Ireland) |
| eu-central-1 | EU (Frankfurt) |
| us-west-2 | EU (London) |
| ap-northeast-1 | Asia Pacific (Tokyo) |
| ap-northeast-2 | Asia Pacific (Seoul) |
| ap-southeast-1 | Asia Pacific (Singapore) |
| ap-southeast-2 | Asia Pacific (Sydney) |
| ap-south-1 | Asia Pacific (Mumbai) |
| sa-east-1 | South America (São Paulo) |
| AWS GovCloud (US) | AWS GovCloud (US) |
| China (Beijing) | China Beijing |
这次出事的就是us-east-1,北佛吉尼亚地区。
AWS的服务就运行在每个地区里,为了进一步减小服务故障对整个地区的影响,每种服务又被分成多个单元(cell或shard)。从客户来的服务请求,由Route 53(Amazon DNS服务)进行负载均衡,每个客户的请求被分配到某个单元中。这样,即便有故障发生,故障的基本上会被限制在单元内,受影响的客户应该会有限。这个分配功能是由Route 53中的Infima库来实现。
一般来说,sharding是通过某种hashing算法来实现。比如,可以对客户ID,操作类型,或者目标资源ID进行hashing。下图显示8个instance被分为4个shard【4】:
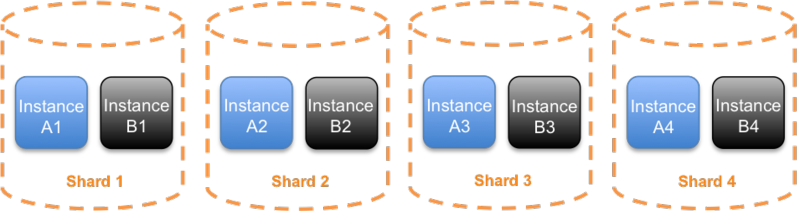
这种sharding方式,在四个shard的情况下,如果错误是由服务请求引起的,那么25%的客户会被影响。为了尽可能降低被影响的客户数,就需要增加shard数。Shuffle sharding算法通过动态生成shard来达到这个目的。比如,还是8个instance,可以有28(8*7/2)种组合。Shuffle sharding的一个要点是客户端要有容错性。在客户端加上重试机制,这样,假设下图中的Shuffle shard 1出错了,instance 3和5无法使用。虽然Shuffle shard 2中也有instance 5,但通过重试,Shuffle shard 2的客户是可以连接到instance 4上,这样这个shard的客户不会受影响。
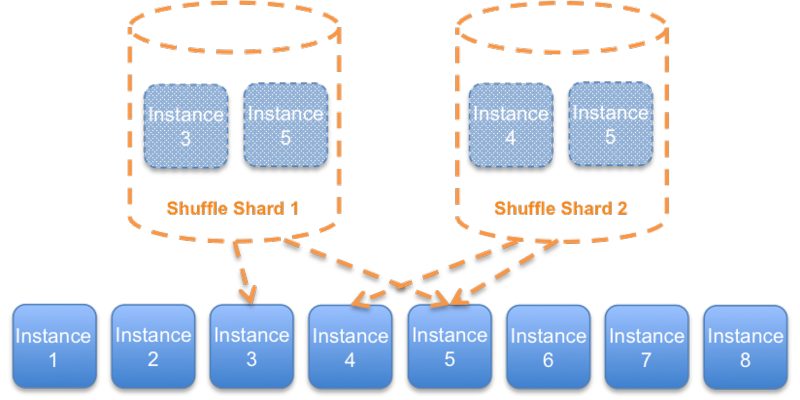
Shuffle shard的一个好处是,通过增加每个shard中的实例数,可以大大增加Shuffle shard数,在客户端适当增加重试数,可以极大降低由于请求错误对客户的影响。比如,如果每个shard中有四个实例,就可以有70种组合(8765/43*2)。
Amazon Route 53 Infima库支持两种Shuffle shard算法:一种是简单无状态shuffle shard,另一种是有状态搜索shuffle shard。两者的差别在于:有状态算法可以保证新的shard和已经生成的shard之间的实例重合度满足要求,比如,我们可以要求每个shard中的四个instance最多允许只有两个instance可以与其它shard重合。
S3存储系统中有多个子系统,其中的索引子系统管理一个地区的所有S3对象的metadata和位置信息。所有S3的API(包括GET,LIST,PUT,和DELETE)都依赖于这个子系统。另一个叫placement的子系统的主要功能是负责分配新的存储,这个子系统依赖于索引子系统。如果索引子系统出了问题,那么这个placement子系统也不能正常工作。
2月28日的事故的原因是运维人员不小心关闭了过多的服务器,导致运行S3子系统的服务器不足。在这种情况下,这些系统会做一次完全的重启。在重启的过程中,S3就需要停止服务用户的请求。但是,按照我们前面描述的系统架构,S3的子系统在设计上应该可以抵御大规模服务器失效的。实际上,AWS的各种运维也要依靠对服务器的关闭和替代。那么,这次的服务器关闭为什么破坏性这么大?究其原因,还是系统部署并没有完全遵从设计:第一,虽然有单元设计,但索引子系统其实并没有单元化,所以这个子系统的故障导致整个地区的用户都受到影响;第二,自从开始S3服务起很多年了,索引和placement子系统就没有被完全重启过,也就是说,从来没有完全按运维要求来操作,管理这些子系统;另外,由于索引子系统过于庞大,重启所花费的时间极大,所以这次事故花了超过四个小时才恢复。

这次事故也暴露了AWS运维工具方面的一些问题。整个事故过程中,AWS的服务健康仪表盘(SHD)一直显示正常,是因为SHD依赖于S3服务,并且,这么重要的工具,竟然没有提供跨地区的可靠性性设计,所以某个地区的S3服务出故障,这个地区的SHD也出故障。这让很多用户不爽。
【参考文献】
- http://www.foxbusiness.com/markets/2017/03/02/amazon-finds-cause-its-outage-typo.html
- Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region
- https://aws.amazon.com/about-aws/global-infrastructure/
- https://www.awsarchitectureblog.com/2014/04/shuffle-sharding.html